
Der Begriff „Künstliche Intelligenz" (KI) steht seit mehreren Jahren aufgrund zahlreicher technischer Fortschritte und damit einhergehender, greifbarer Entwicklungen, etwa im Bereich des autonomen Fahrens oder der automatischen Gesichtserkennung, im Fokus der gesellschaftlichen Aufmerksamkeit.
 Dieser Beitrag ist ein Auszug aus der „Gutachterlichen Stellungnahme zu den Auswirkungen künstlicher Systeme und der Digitalisierung auf das kommunale Leben in Rheinland-Pfalz 2050“. Die gesamte Studie steht unter ea-rlp.de/earlpdigital2019 zum Download als PDF (88 Seiten, 18 MB) bereit.
Dieser Beitrag ist ein Auszug aus der „Gutachterlichen Stellungnahme zu den Auswirkungen künstlicher Systeme und der Digitalisierung auf das kommunale Leben in Rheinland-Pfalz 2050“. Die gesamte Studie steht unter ea-rlp.de/earlpdigital2019 zum Download als PDF (88 Seiten, 18 MB) bereit.
Auszug 1 – Künstliche Intelligenz: Konzepte und Technologien
Auszug 2 – Fünf Beispiele: Chancen durch KI in Landwirtschaft, Gesundheit, Ehrenamt, Tourismus und Mobilität in RLP
Auszug 3 – Szenarien für Rheinland-Pfalz: Zwischen Dystopie und Utopie
Zusammenfassung
Autorinnen und Autoren: Matthias Berg (Fraunhofer IESE), Christoph Giehl (Stadtsoziologie TU Kaiserslautern), Matthias Koch (Fraunhofer IESE), Martin Memmel (DFKI), Annette Spellerberg (Leitung; Stadtsoziologie TU Kaiserslautern), Ricarda Walter (Stadtsoziologie TU Kaiserslautern); unter Mitarbeit von: Steffen Hess, Andreas Jedlitschka, Michael Klaes, Dieter Lerner, Adam Trendowicz (Fraunhofer IESE).
Themen wie die wirtschaftliche Relevanz von KI, ihre Bedeutung für den (Wirtschafts-) Standort Deutschland, ethische Fragestellungen und durch KI-Anwendungen (mit-)verursachte gesellschaftliche Veränderungen werden in vielfältigen Foren und Medien diskutiert. Eine fundierte Definition des Begriffs „Künstliche Intelligenz" und eine Einordnung der Fähigkeiten von KI-Systemen, etwa anhand der Ursprünge und bisherigen Entwicklungen in dieser vergleichsweise neuen Disziplin der Informatik, findet jedoch nur selten statt. Dies ist jedoch von essenzieller Bedeutung, um den aktuellen Stand der Diskussion verstehen und zukünftig mögliche Szenarios einschätzen zu können. Im Folgenden wird daher zunächst eine kurze Einführung des Begriffs ,,Künstliche Intelligenz" sowie ein Überblick über seine Entstehungsgeschichte gegeben. Daran schließt sich ein Überblick über die wichtigsten Konzepten und Technologien an, die aktuell im Kontext der KI relevant sind.
Definition und kurze Historie
Unter dem Begriff „Künstliche Intelligenz" wurden insbesondere im Kontext der medialen Berichterstattung der letzten Jahre zahlreiche Themen und Technologien subsummiert. Es gibt zwar keine einheitliche Definition des Begriffs, aber dennoch wird er, durchaus auch oft in zweifelhafter Weise, verwendet, um etwa die Popularität des Themas zum Generieren von Aufmerksamkeit zu nutzen.

Es ist nicht Ziel dieses Gutachtens, eine eigene Definition des Begriffs vorzugeben, vielmehr wird versucht wir, ihn adäquat einzuschränken und die zur Beurteilung seiner Verwendung notwendigen Informationen zu vermitteln.
„Künstliche Intelligenz" ist zum einen eine Teildisziplin der Informatik, zum anderen aber auch ein „Sammelbegriff für diejenigen Technologien und ihre Anwendungen, die durch digitale Methoden auf der Grundlage potenziell sehr großer und heterogener Datensätze in einem komplexen und die menschliche Intelligenz gleichsam nachahmenden maschinellen Verarbeitungsprozess ein Ergebnis ermitteln, das ggf. automatisiert zur Anwendung gebracht wird" (Datenethikkommission KI 2018, 1).
Zu entscheiden, ob eine Technologie oder Anwendung „intelligentes Verhalten" zeigt, hängt unmittelbar mit der Definition des Intelligenzbegriffes zusammen. Um sich intelligent zu verhalten, sind in unterschiedlichen Anteilen bestimmte Kernfähigkeiten notwendig:
Wahrnehmen, Verstehen, Planen, Handeln und Lernen (Burchardt 2018, 13). Entsprechend gibt es auch verschiedene Ausprägungen „Künstlicher Intelligenz". Man unterscheidet daher auch zwischen „schwacher KI" und „starker KI". Schwache KI dient als Sammelbegriff für Technologien mit starkem Anwendungsbezug und dem Ziel einer sehr konkreten Lösung in einem klar definierten, vorgegebenen Problemkontext. Alle heutigen KI-Systeme fallen in die Kategorie dieser schwachen KI. Die starke KI hat im Gegensatz dazu ein sehr viel weitergehendes und ambitionierteres Ziel: Sie versucht, die vollständigen intellektuellen Fertigkeiten von Menschen unabhängig von einem konkreten Problemkontext zu imitieren oder gar zu übertreffen.
Dabei ist die Idee intelligenter Maschinen keine neue, und „intelligente" Maschinen wurden bereits in der Ära vor dem Aufkommen der Computer mithilfe von klassischen mechanischen Ansätzen in oft spielerischer Art und Weise umgesetzt. Eine völlig neue Dimension erhielt das Thema jedoch mit dem Aufkommen der Digitalrechner. Mit diesen stand erstmals eine adäquate Technologie zur Simulation „berechenbarer Aspekte" der Intelligenz zur Verfügung. Es wurden spezielle Programmiersprachen zur Modellierung kognitiver Prozesse entwickelt, mit denen die Simulation des eigenen intelligenten Verhaltens möglich wurde.
Als Geburtsstunde der KI gilt die im Jahr 1956 von den US-amerikanischen Forschern John McCarthy, Marvin Minsky, Nathaniel Rochester und Claude Shannon am Dartmouth College initiierte Dartmouth-Konferenz in Hanover, New Hampshire, USA. Zu den Kernaussagen dieser Konferenz gehören:
- Sämtliche Eigenschaften der Intelligenz lassen sich in Form abstrakter Modelle präzise beschreiben.
- Denkprozesse sind nicht ausschließlich dem menschlichen Gehirn vorbehalten.
- Computer sind das beste außermenschliche Instrument für diese Denkprozesse.
In den darauffolgenden Jahren unterlag die Popularität des Themas „Künstliche Intelligenz" immer wieder größeren Schwankungen. Der bis etwa 1969 andauernden Phase des Aufbruchs und der Begeisterung folgte etwa eine durch fundamentale Schwierigkeiten speziell aufgrund fehlenden Wissens von Programmen über Anwendungsgebiete gekennzeichnete Phase der Ernüchterung. In den 1980er Jahren wiederum gab es zahlreiche kommerzielle Erfolge beim Einsatz von Expertensystemen in der Industrie; es wurden KI-Abteilungen in vielen größeren Firmen gegründet, und Kl-basierte Projekte wurden im großen Stil gefördert. In diese Phase fiel auch die Gründung des Deutschen Forschungszentrums für Künstliche Intelligenz (DFKI) im Jahr 1988.
Nach einer Phase der Konsolidierung hat das Thema „Künstliche Intelligenz" nun auch für Politik und Entscheidungsträger große Bedeutung erlangt, hauptsächlich bedingt durch die großen und sichtbaren Fortschritte im Bereich Deep Learning und durch die Durchdringung aller Lebensbereiche mit digitalen Technologien.
Konzepte und Technologien
Die Entwicklung neuer Technologien erfolgt nicht auf linearen, festgelegten Pfaden, sondern zeichnet sich durch Höhen und Tiefen aus, durch Zeiten des Aufbruchs und der Enttäuschung. Dennoch lassen sich neue, aufkommende Technologien einordnen, um deren Zustand und Auswirkungen zu begreifen. Das Marktforschungsunternehmen Gartner veröffentlicht Jahr für Jahr seinen sogenannten „Hype Cycle", eine Illustration, die Technologien auf einer Kurve von überhöhten Erwartungen durch ein Tal der Enttäuschungen zu einem Plateau der Produktivität einzeichnet.
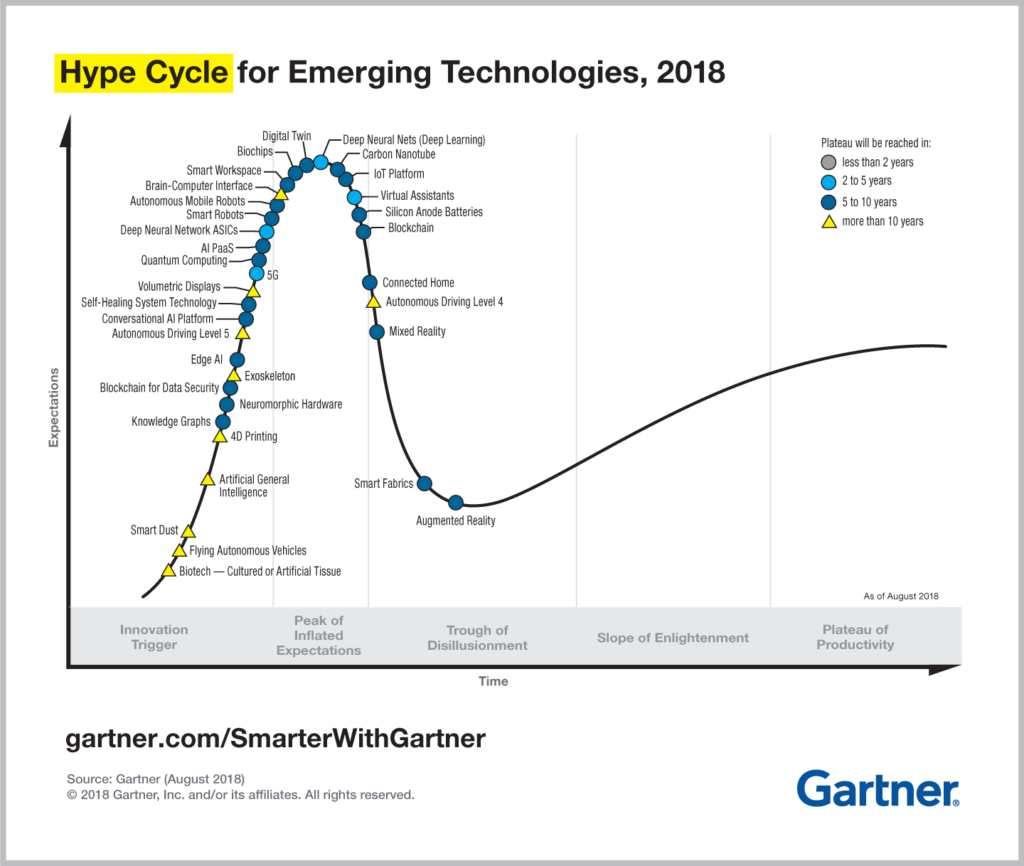
Die Abbildung zeigt den „Hype Cycle" für das Jahr 2018. Es ist erkennbar, dass Künstliche Intelligenz und verwandte Technologien hohen Erwartungen ausgesetzt sind. Im folgenden Abschnitt werden nicht alle aktuellen Technologien beschreiben, die im Kontext von KI relevant sind, sondern es wird vielmehr eine Auswahl an Technologien kurz erläutert. Hiermit werden die Grundlagen für die späteren Ausführungen zu Künstlicher Intelligenz und ihren denkbaren Auswirkungen in Kommunen gelegt.
Big Data
Der Begriff Big Data ist ein Sammelbegriff für die Verarbeitung von Massendaten. Kennzeichnende Merkmale von Big Data sind die drei Dimensionen Volume (zu verarbeitende Datenmenge), Velocity (Geschwindigkeit, mit der Daten generiert und verarbeitet werden) und Variety (Vielfalt an zu verarbeitenden Datentypen wie Zahlen, Texte oder Bilder).
Aufgrund der riesigen Datenmengen und der großen Geschwindigkeit, mit der diese Daten generiert werden, ist eine Verarbeitung mit herkömmlichen sequentiellen Methoden der Datenverarbeitung nicht mehr möglich. Stattdessen ist eine Parallelverarbeitung notwendig. Hierzu werden die Daten zunächst partitioniert und auf einem Verbund (Cluster) von Rechnern (Knoten) verteilt. Alle Rechner des Verbundes verarbeiten anschließend zeitgleich die ihnen zugeteilten Datenpartitionen. Abschließend wird das Gesamtergebnis aus den Einzelergebnissen jedes Knotens berechnet.
Mit diesem Ansatz der Parallelverarbeitung ist es möglich, große Datenmengen mit hoher Geschwindigkeit zu verarbeiten. Die Anzahl der Knoten in einem Verbund kann hierbei an die Datenmenge und die erforderliche Verarbeitungsgeschwindigkeit angepasst werden. Für kleinere Unternehmen können schon einige wenige Knoten ausreichen. Die Cluster großer digitalisierter Unternehmen bestehen hingegen aus Hunderten oder gar Tausenden von Knoten. Ein Cluster für Big Data kann lokal in einem Unternehmen (on Premise) oder auch mit geringem Aufwand in einer Cloud-Umgebung realisiert werden.
Softwaresysteme für Big Data lassen sich grob in zwei Klassen unterteilen: Systeme für die Speicherung (NoSQL-Datenbanken) und Systeme zur schnellen Verarbeitung und Analyse großer Datenmengen. Ergänzend werden spezialisierte Systeme z.B. für den Import großer Datenmengen oder für Datentransformationen eingesetzt.
Data Mining (Probabilistik, Statistik)
Will man Erkenntnisse über Muster oder Strukturen in großen oder sogar sehr großen Datenmengen (Stichwort „Big Data") gewinnen, so ist dies mit simplen manuellen Analysen nicht möglich. Auch Visualisierungen in Form von Diagrammen oder Schaubildern stoßen schnell an Ihre Grenzen. Eine Datenanalyse muss somit wenigstens teilweise automatisiert sein. Die Forschungs- bzw. Anwendungsgebiete „Knowledge Discovery in Databases" (KDD) sowie „Data Mining" beschäftigen sich mit Methoden, intelligente und rechnergestützte Verfahren für die Datenanalyse zu entwickeln. Witten und Frank (2011) definieren den Begriff „Data Mining" wie folgt: ,,Beim Data Mining geht es darum, Modelle zu bilden, die Regularitäten und Zusammenhänge in großen Datenmengen erklären."
Typische Aufgaben im Data Mining sind etwa Klassifikation, Segmentierung, Clustering, Vorhersage, Trendanalyse oder Abhängigkeits- bzw. Assoziationsanalyse. Sie werden in einer Vielzahl an Branchen eingesetzt, etwa im Direktmarketing und in der Finanz- und Versicherungswirtschaft.
Beim Data Mining handelt es sich stets um einen Prozess, in dem Mensch und Maschine interagieren und bei dem Expertenwissen über die Anwendungsdomäne und mögliche Technologien unerlässlich ist. Data Mining Tools assistieren dem Menschen bei der Datenanalyse, können diesen jedoch nicht ersetzen. Der Mensch wählt zunächst Daten aus, bestimmt notwendige Schritte für eine Vorverarbeitung dieser Daten und wählt und parametrisiert Methoden. Hier stehen zahlreiche Verfahren bzw. Technologien zur Verfügung, z.B. klassische Statistik, Entscheidungsbäume, Bayes-Klassifikatoren oder Künstliche Neuronale Netze. Nachdem die Maschine Modelle vorschlägt und quantitative Bewertungen erstellt hat, analysiert der Mensch Qualität und Nützlichkeit und akzeptiert oder verwirft die Modelle. Dabei werden verschiedene Qualitätskriterien für Wissen wie Korrektheit, Allgemeinheit, Nützlichkeit, Verständlichkeit oder Neuheit herangezogen.
Machine Learning

Anstatt wie bei wissensbasierten Systemen das benötigte Wissen in einem manuellen oder nur teilautomatisierten Prozess zur Verfügung zu stellen, verfolgt das maschinelle Lernen das Ziel, selbstständig basierend auf zur Verfügung gestellten Daten Muster zu erkennen bzw. Modelle zu lernen. Machine Learning ist eine Schlüsseltechnologie der Künstlichen Intelligenz und ein Oberbegriff für zahlreiche Verfahren.
Man unterscheidet dabei grundsätzlich zwischen überwachtem und unüberwachtem Lernen. Im ersteren Fall kennt das System bereits die korrekten Antworten bzw. Hypothesen und versucht mithilfe dieser Informationen ein Modell zu lernen. Beim unüberwachten Lernen ist dagegen noch nicht bekannt, was gelernt werden soll.
Eine weitere prominente Klasse an Verfahren wird als bestärkendes oder verstärkendes Lernen (reinforcement learning) bezeichnet. Hierbei reagiert ein System auf positive Rückmeldungen bzw. Belohnungen und erlernt so selbstständig ein Modell mit dem Ziel, möglichst viele Belohnungen zu erhalten.
Deep Learning
Der Begriff Deep Learning bezeichnet eine spezielle Klasse von Optimierungsmethoden von Künstlichen Neuronalen Netzen (KNN), einem Teilbereich des Machine Learnings. Sie werden oft auch als „Deep Neural Networks" bezeichnet und stehen seit einigen Jahren beinahe stellvertretend für die zunehmend größere Bedeutung des Themas Künstliche Intelligenz im öffentlichen Diskurs.
Obwohl die beim Deep Learning verwendeten Verfahren nicht neu sind, wurde mit der immer größer werdenden Menge an zur Verfügung stehenden Daten sowie der enormen Leistungssteigerung bei der Verarbeitung dieser Daten der Stand der Technik in zahlreichen Anwendungsbereichen wie etwa Bilderkennung und Spracherkennung dramatisch verbessert (LeCun et al. 2015).
Die Lernmethoden solcher Künstlichen Neuronalen Netze richten sich zwar nach der Funktionsweise des menschlichen Gehirns und resultieren in der Fähigkeit zu eigenen Prognosen oder Entscheidungen, allerdings beruhen diese Vorgehensweisen auf Erkenntnissen der Hirnforschung aus den 1960er Jahren (Thielicke 2018). Es ist davon auszugehen, das mit dem zunehmenden Verständnis der Abläufe im menschlichen Gehirn auch völlig neue Verfahren in der Künstlichen Intelligenz entwickelt werden, die zum Teil auch auf völlig neuen Computerarchitekturen beruhen.
Autonomisierung bzw. Autonome Systeme
Autonome Systeme haben die Fähigkeit, komplexe Aufgaben eigenständig zu bewältigen. Beispiele sind autonome Fahr- bzw. Flugzeuge und autonome Roboter. Wesentlicher Gesichtspunkt dabei ist die Unabhängigkeit der Diensterbringung vom menschlichen Bediener. Im Bereich der autonomen Fahrzeuge unterscheidet man sechs Autonomiestufen (0: Selbstfahrer, 1: Fahrerassistenz, 2: Teilautomatisierung, 3: Bedingungsautomatisierung, 4: Hochautomatisierung, 5: Vollautomatisierung). In den Stufen 0-2 wird die Umgebung vom menschlichen Fahrer kontrolliert, in den Stufen 3-5 vom System. Auf dem deutschen Markt befinden sich Systeme der Stufe 2, wobei in den USA auch eingeschränkt Stufe 3 (z.B. bei Tesla) eingesetzt wird. Prototypen in Stufe 5 werden derzeit von allen großen Anbietern und Zulieferern getestet.
Weitergehende Automatisierung setzt neben Prozesswissen ein zunehmendes Verständnis des Kontexts, z. B. durch Sensorik oder gelieferte Daten, eine analytische Betrachtung der Situation sowie eine angebrachte Reaktion voraus. Ein autonomes Fahrzeug muss also neben dem Wissen darüber, wie Fahren funktioniert, auch „verstehen", wie es die Fahrweise an eine sich verändernde (oft unbekannte) Umwelt anzupassen hat. Die Sicherstellung einer angebrachten Reaktion ist eine der großen Herausforderungen, da sowohl technische (algorithmische) als auch rechtliche und ethische Aspekte zu betrachten sind. Insbesondere die Verwendung der aktuell stark propagierten Ansätze aus dem maschinellen Lernen sind aus Sicht der funktionalen Sicherheitsbeurteilung schwierig zu bewerten, da sie nicht deterministisch sind, was bedeutet, dass sie bei gleichem Ausgangspunkt nicht immer zum selben Ergebnis führen. Aus ethischer Sicht befinden wir uns im Falle eines unausweichlichen Unfalls in der Situation, dass, im Gegensatz zum Menschen, der eine unbewusste Entscheidung treffen wird, die in keiner Weise „optimal" im Sinne des Schadens sein muss, die Maschine eine „bewusste Entscheidung" treffen müssen wird. Die Ethikkommission hat einen Bericht mit 20 Thesen zum automatisierten Fahren vorgelegt, der als Leitlinie für zukünftige Systeme gelten soll.
Robotik
Das interdisziplinäre Feld der Robotik beschäftigt sich mit der Konzeption, der Konstruktion, dem Betrieb und dem Einsatz von Robotern sowie Computersystemen für deren Steuerung. Robotik umfasst Ansätze aus zahlreichen Feldern der Ingenieurwissenschaften und Wissenschaften wie Maschinenbau, Elektrotechnik, Informationstechnik, Informatik (insbesondere Künstliche Intelligenz), Mensch-Maschine-Interaktion, Psychologie, Soziologie und Philosophie.

,,Roboter" bezeichnet dabei eine üblicherweise von einem Computer programmierte Maschine, die in der Lage ist, eine komplexe Reihe von Aktionen automatisch auszuführen. Dabei können autonome und semiautonome Roboter unterschieden werden. Roboter gibt es in unterschiedlichsten Formen, von Humanoiden über Industrieroboter und medizinische Operationsroboter bis hin zu Drohnen oder mikroskopischen Nano-Robotern. Sie stellen eine spezielle Form autonomer Systeme dar, die mit ihrer Umwelt physisch interagieren können.
Auch wenn in den letzten Jahren enorme Fortschritte etwa im Bereich von humanoiden Robotern und Laufrobotern erzielt werden konnten, sind die Systeme heute immer noch sehr limitiert. So kann beispielsweise der von Honda entwickelte Roboter ASIMO zwar mit Menschen in gewissem Maße interagieren, allerdings nur in begrenztem Umfang und weitgehend beschränkt auf vordefinierte Szenarien (Hirose und Ogawa 2007). Die komplexe Interaktion zwischen Robotern und Menschen in offenen, nicht vordefinierten Umgebungen ist noch heute ein ungelöstes Problem und Thema zahlreicher Forschungsbemühungen auf dem Gebiet der Künstlichen Intelligenz und der Mensch-Roboter-Interaktion (Schwartz et al. 2016).
Im Bereich Industrie 4.0 übernehmen Maschinen (Roboter wie Software) immer mehr Aufgaben, die bisher von Menschen durchgeführt wurden. Dabei werden nicht nur reine Produktionsaufgaben von Maschinen übernommen, sondern auch Planung und Entscheidungen. Wenn früher die Maschine als einfacher Verrichter angesehen wurde, wird sie heute schon als kollaborativer Co-Worker verstanden. Das heißt, sie arbeitet gleichberechtigt mit. Die Auswirkungen auf die Gesellschaft sind unklar und reichen von der dystopischen Vorstellung, dass die meisten Arbeitsplätze wegfallen, zu eher beruhigenden Szenarien, wie sie u.a. vom McKinsey Global Institute vorhergesagt werden, nach dessen Meinung die Automatisierung mehr Stellen verändern als wegrationalisieren wird.
Plattformökonomie
Digitale Geschäftsmodelle spielen eine zunehmend wichtigere Rolle auf den Weltmärkten. Gegenüber traditioneller Wertschöpfung, welche auf der Herstellung von Produkten und deren Vertrieb an Kunden basiert, setzen heutige digitale Geschäftsmodelle zumeist auf eine plattformbasierte Wertschöpfung. Bereits im Jahr 2016 bestätigten 81 % der Manager einer von Accenture durchgeführten Studie die zentrale Bedeutung plattformbasierter Geschäftsmodelle für ihre Wachstumsstrategie innerhalb der nächsten drei Jahr. Eine auf Plattformen basierende Strategie zeichnet aus, dass sie, anders als eine reine Produktstrategie, auf ein Ökosystem setzt, das die Generierung von Produkt- oder Dienstleistungsinnovationen und Synergien zwischen diesen Angeboten potenziell vieler beteiligter Organisationen und der Plattform ermöglicht. Die Kernidee einer Plattform ist, dass Partner Angebote nutzen und selbst Beiträge bereitstellen, wodurch die Wertschöpfung realisiert wird.

Prominente Beispiele für derartige Konzepte sind vor allem im Bereich der sozialen Medien zu finden, wie Facebook und Linkedln, aber auch eBay und Amazon im Einzelhandel oder Netflix und Spotify in der Unterhaltungsbranche. Anhand der Musikindustrie lässt sich illustrieren, welche disruptiven Veränderungen durch Digitalisierung und den Wandel hin zu Plattformen vonstattengehen können. So hat bereits vor der Jahrtausendwende die CD als digitales Produkt die analoge Vinyl-Schallplatte ersetzt. Einen Schritt weiter ging nach der Jahrtausendwende der Trend zum Download von Musikstücken anstatt des Kaufs von Musik auf Datenträgern. Während die erste Veränderung wenig Einfluss auf die Künstler und den Vertrieb von Musik hatte, machte der zweite Digitalisierungsschritt aufgrund des neuen Kanals, über den Hörer Musik erwerben, die Presswerke und Plattenläden teilweise obsolet. In den vergangenen Jahren lässt sich der Trend zum Streaming von Musik beobachten. Dieser bedeutet, dass Musik nicht mehr über den Kauf von Datenträgern oder den Download einzelner Musikstücke gekauft wird, sondern dass gegen eine feste Gebühr der unbegrenzte Zugriff auf Musik gewährt wird. Dadurch verändert sich sowohl der „Kauf“ als auch der Vertrieb von Musik drastisch, einhergehend mit neuen Geschäftsopportunitäten und -modellen.
Ermöglicht wird dieses Angebot durch Plattformen, die den Dienst des Musikstreamings bereitstellen, aber auch offen für weitere Funktionalitäten sind und dadurch Kunden an das die Plattform betreibende Unternehmen binden. Auf diesem Weg wird die Plattform zu einem eigenen Ökosystem, das durch die Integration diverser Angebote die Bedürfnisse der Nutzer in einem Themengebiet, zum Beispiel Musik, umfassend und komfortabel zufriedenstellt. Diese Angebote können Komponenten wie Bezahlung, Rechteverwaltung und Datenanalyse beinhalten. Die Vielfalt macht hierbei deutlich, dass Plattformen trotz Fokussierung auf eine Branche dennoch breit aufgestellt sind und Dienste aus diversen Domänen einbinden müssen.
Biologisierung und Smart Ecosystems
Der Begriff des Ökosystems fiel bereits im vorherigen Kapitel. Die Nutzung der Metapher eines Ökosystems in der Geschäftswelt ist spätestens seit James Moores Buch „The Death of Competition" aus dem Jahr 1997 geläufig (Moore 1997). Nach und nach wurde der Begriff auch für weitere „Ökosysteme" etabliert, darunter sogenannte Software-Ökosysteme (Messerschmitt, Szyperski 2003). Unter Software-Ökosystemen versteht man das Zusammenspiel aus Organisationen und Unternehmen, die als eine Einheit funktionieren und auf einer gemeinsamen technischen Plattform interagieren, um Produkte und Dienstleistungen anzubieten. Darauf aufbauend etabliert sich mehr und mehr der Begriff des „digitalen Ökosystems". Die Güter, die in einem solchen Ökosystem gehandelt werden, werden durch Software ermöglicht, sind jedoch nicht die Software an sich. Beispiele können hier Musik oder Transportmöglichkeiten sein, die über ein digitales Ökosystem von Partnern über eine Plattform angeboten werden.
Anders als ein biologisches Ökosystem, von dem die Bezeichnung entlehnt ist, werden digitale Ökosysteme explizit kreiert. Der „Schöpfer" des digitalen Ökosystems bestimmt die Regeln, an die sich Partner halten müssen, wenn sie partizipieren möchten. Darüber hinaus profitiert der Betreiber des Ökosystems mit seiner zentralen Plattform, über die die Daten und Dienste im Ökosystem fließen, von allen Transaktionen im Ökosystem. Damit Transaktionen über die Plattform des Ökosystems abgewickelt werden, muss der Betreiber den Fokus auf die Koordination des Zusammenwirkens einzelner Dienste externer Partner legen. Analog zu sozialen Verbänden in der Biologie gibt es keine festen Strukturen, weil sich die Zusammensetzung der Partner und ihrer Aktivitäten im Ökosystem kontinuierlich ändert. Stattdessen spricht man von „Verhaltensregeln" und einer gemeinsamen ,,Sprache" sowie gemeinsamen „Werten", die die Zusammenarbeit im Ökosystem lenken. Aufgrund der Selbstständigkeit der Partner, die auch während der Teilnahme am Ökosystem gewahrt bleibt, können diese jederzeit beschließen, das Ökosystem zu verlassen.
Diese Zu- und Abgänge entwickeln eine Dynamik ähnlich den autonomen und dynamischen Anpassungen in der Biologie. Folglich muss auch ein digitales Ökosystem in der Lage sein, auf Veränderungen angemessen zu reagieren und gegebenenfalls selbstständig Anpassungen vorzunehmen. Eine weitere Analogie zur Biologie wird in Bezug zur „Intelligenz" solcher Systeme gezogen, die notwendig ist, um die erforderlichen Anpassungen vorzunehmen. Selbst wenn keine Intelligenz im Sinne des menschlichen Bewusstseins damit gemeint ist, so geht es doch um eine künstliche Intelligenz, die biologische Intelligenz nachahmt. Schließlich gilt im Ökosystem, wie in der Biologie auch, dass die Gesamtheit der Einzelsysteme mehr bieten kann als die Einzelsysteme alleine. Aus diesem Grund lassen sich aus dem Zusammenwirken in der Biologie Inspirationen für die Gestaltung digitaler Ökosysteme gewinnen.
Internet der Dinge
Die Bezeichnung „Internet der Dinge" ist ein Sammelbegriff für verschiedene Technologien und Anwendungen, mit denen Objekte aus der realen und virtuellen Welt vernetzt werden können, womit die Basis für vielfältige (erweiterte) Interaktionen mit bzw. zwischen diesen Objekten ermöglicht wird. Die zugrundeliegenden Ideen hierfür wurden schon Anfang der 1990er Jahre unter dem Begriff „Ubiquitous Computing" eingeführt (Weiser 1991 ); es bestehen zudem zahlreiche Bezüge zum Themenfeld „Embedded Systems".
Das Internet der Dinge zeichnet sich vor allem dadurch aus, dass Objekte eindeutig adressierbar bzw. identifizierbar sind und vielfach selbst mit eingebetteter Technologie wie etwa Sensorik oder RFID-Chips ausgestattet sind (ein prominentes Beispiel hierfür sind sogenannte „Wearables" wie SmartWatches oder Fitnessarmbänder). Mattem und Flörkemeier (2010) führen folgende Aspekte auf, aufgrund derer das „Internet der Dinge" in seiner Gesamtheit zu einer neuen Qualität der Technikentwicklung führt: Kommunikation und Kooperation, Adressierbarkeit, Identifikation, Sensorik, Effektorik, Lokalisierung und Benutzungsschnittstelle. Zu den prominentesten Anwendungsfeldern im Themenfeld des „Internet der Dinge" gehören Smart Horne, Mobilität, Logistik und Gesundheitswesen.
Blockchain
Die Blockchain erlangte Bekanntheit durch ihre Rolle als Basistechnologie der seit 2009 im Umlauf befindlichen Kryptowährung Bitcoin. Seit diesem Zeitpunkt wurde die Blockchain-Technologie bei der Schaffung zahlreicher weiterer digitaler Zahlungsmittel verwendet, um Buchungssysteme zu realisieren, die von der Existenz einer zentralen vertrauenswürdigen Stelle (z. B. Banken oder Notare) unabhängig sind.
Die Blockchain-Technologie erlaubt hierbei das dezentrale Führen einer Datenbank, deren Korrektheit auf Basis einer Konsensbildung der Beteiligten sichergestellt wird. Jede einzelne Transaktion ist unleugbar und automatisch prüfbar. Manipulationsversuche an erfolgreich vorgenommenen Einträgen sind durch eine kryptografische Verknüpfung der die gesamte Transaktionshistorie beinhaltenden Datenblöcke für alle Beteiligten direkt erkennbar.
Die Blockchain-Technologie scheint daher neben ihrem Einsatz bei Kryptowährungen in weiteren Bereichen neue Chancen zu bieten, teilweise auch in Form disruptiver Geschäftsmodelle. Sie ermöglicht z. B. Smart Contracts, bei denen sich die Regelungen eines Vertrags elektronisch abbilden lassen. Aktuell wird die Konzeption und Entwicklung erster Prototypen in zahlreichen Branchen insbesondere durch Start-ups vorangetrieben.
Augmented Reality
Eine einheitliche Definition zu Augmented Reality (AR) gibt es in der Literatur nicht. Zur begrifflichen Klärung wird häufig auf das Reality-Virtuality Continuum von Milgram et al. (1994) Bezug genommen. Dabei wird AR als jede Technologie beschrieben, die reale und virtuelle Informationen sinnvoll kombinieren kann. In einer weiteren Definition zu AR von Azuma (1997) ist AR durch folgende Charakteristika definiert: (1) Kombination von virtueller Realität und realer Umwelt mit teilweiser Überlagerung, (2) Interaktion in Echtzeit und (3) dreidimensionaler Bezug virtueller und realer Objekte (Mehler-Bicher und Steiger 2017). Die virtuellen Informationen werden hierbei in das Sichtfeld eines Betrachters eingeblendet. Der Benutzer ist mit einem mobilen Endgerät oder einer Datenbrille ausgestattet. Dabei können in technologischer Hinsicht vier Ebenen der AR unterschieden werden: Ebene 1: QR-Code-basierte Aktivierung von damit verbundenen Informationen (Hyperlinks, Bilder, Texte, Audios, Videos usw.). Ebene 2: Markerbasierte (Trigger, Tracker, Targets oder Image) Aktivierung virtueller Zusatzinformationen (z. B. Einblenden eines 3DModells). Ebene 3: Markerlose Aktivierung virtueller Informationen. Hierbei erkennt eine in das mobile Endgerät bzw. in die Datenbrille integrierte Kamera die Kontur bzw. Struktur eines realen Objektes, oder ein integriertes GPS löst über die Verarbeitung geografischer Daten an einem bestimmten Standpunkt die Aktivierung der virtuellen Informationen aus. Ebene 4: Bei der sogenannten immersiven AR wird über die nicht- oder halbtransparente Datenbrille eine virtuelle 3D-Welt direkt in das Blickfeld des Benutzers eingespielt (Castellanos und Perez 2017).

Um AR-Anwendungen der Ebene 4 zu ermöglichen, ist es notwendig, zunächst die reale Umgebung zu erfassen (über nicht-visuelles oder visuelles Tracking), um anschließend diese Umgebung um virtuelle Objekte und Informationen zu ergänzen (Realitätserweiterung). Der Benutzer trägt dabei eine Datenbrille (als Head-Mounted Display; HMD) mit oder ohne ein sogenanntes See-Through Display. Beim HMD-Prinzip ist die Kamera am Kopf des Betrachters montiert. Dadurch kann sie bei Kopfbewegungen die reale Umgebung erfassen und entweder nach Markern oder nach natürlichen Formen (Marker- oder Markerless Tracking) suchen. Die Projektion erfolgt auf ein Display, das direkt vor den Augen des Betrachters montiert ist. Das Rendering aus realen und virtuellen Bildern wird in seiner Gesamtheit auf das Display projiziert. Alternativ kann der Betrachter durch ein sog. See-Through Display die reale Umgebung erkennen; lediglich die virtuellen Objekte werden zusätzlich in das Display projiziert (Mehler-Bicher und Steiger 2017).
Ähnlich wie bei Virtual Reality existiert mittlerweile eine Vielzahl von Anwendungsszenarien, die häufig auch mit der Bezeichnung „living" versehen sind. Beim „Living Mirror" erkennt eine Kamera das Gesicht des Betrachters und platziert lagegerecht dreidimensionale Objekte auf dem Gesicht bzw. Kopf. Das „Living Print" Szenario basiert auf dem Erkennen eines Printmediums und entsprechender Augmentierung. Beim „Living Game Mobile" bilden mobile Endgeräte die Basis für augmentierte Spiele, die z. B. auf dem Smartphone zur Anwendung gebracht werden. Mithilfe von AR lassen sich Tele- und Videokonferenzen anreichern (,,Living Meeting"), sodass sie fast wie reale zusammentreffen wirken. Weitere Anwendungsbeispiele stellen „Living Architecture" (Vermittlung von Raumeindrücken), ,,Living Poster" (Werbebotschaften im öffentlichen Raum) und „Living Presentations" (augmentierte Messestände und Präsentationen) dar.
Alle AR-Anwendungen, die mit mobilen Systemen reale Umgebungen oder Einrichtungen mit Zusatzinformationen jeglicher Art wie Text, 2D- oder 3D-Objekten, Video- und Audiosequenzen erweitern, bezeichnet man als „Living Environment". Ziel ist zeitnahe Informationsgewinnung (Time-to-Content) durch den Benutzer allein dadurch, dass durch die Kamera ein Objekt oder eine Kombination von Objekten erfasst wird und entsprechende Zusatzinformationen bereitgestellt werden (Mehler-Bicher und Steiger 2017).
Virtual Reality
Der Begriff „Virtuelle Realität" (VR) wird für eine Vielfalt von heterogenen Technologien, Anwendungsgebieten und interdisziplinären Theorie- und Forschungsansätzen verwendet. In technologischer Hinsicht spielen Visualisierungstechniken eine wichtige Rolle. Virtuelle Realitäten können auf einfachen Displays repräsentiert werden. Sie können durch geschlossene VR-Brillen (sog. Head-Mounted Displays) oder in Datenbrillen erzeugt werden, welche die physikalische Realität mit zusätzlichen Informationen überlagern (Augmented Reality). Eine andere Visualisierungstechnik ist die sogenannte CAVE (Cave Automatie Virtual Environment). In einer CAVE werden virtuelle Welten so präsentiert, dass sie dreidimensional mitten im Raum zu stehen scheinen und von den Betrachtern interaktiv in Echtzeit manipuliert werden können (Kuhlen 2014). Neben Visualisierungstechniken werden aber auch Technologien eingesetzt, welche die akustischen und taktilen Sinnesreize des Menschen ansprechen und damit die Gestaltung einer VR als eine multisensorisch wahrnehmbare Welt ermöglichen (Brill 2009). Insofern ist VR eine spezielle Form der Mensch-Computer-Schnittstelle, die mehrere menschliche Sinne in die Interaktion einbezieht und beim Benutzer die Illusion hervorruft, die computergenerierte künstliche Welt als real wahrzunehmen (Kuhlen 2014).

VR-Anwendungsszenarien finden sich inzwischen in zahlreichen Gebieten, so etwa in der Medizin, im Militär, im Bildungsbereich, in verschiedenen Wissenschaftszweigen, in der Industrie sowie im Unterhaltungsbereich. Industrielle Produktionsstraßen werden heute virtuell geplant, auf ihre Leistungsfähigkeit geprüft und gestaltet (Jun et al. 2012). Zu Trainings- und Planungszwecken werden in der Chirurgie virtuelle Operationen durchgeführt (Riva 2014) und diagnostische und therapeutische Entscheidungen mithilfe virtueller Patientensimulationen trainiert (Müller-Wittig 2017). Soldaten und Soldatinnen trainieren den Kampf, Militärstrategen simulieren das Gefecht (Smith 2014). Zu therapeutischen Zwecken werden Patienten virtuell in Situationen gebracht, vor denen diese Phobien haben (Mühlberger 2014). Ein weiteres großes Anwendungsgebiet stellt der Unterhaltungsbereich, insbesondere die Spielebranche, dar (Damer und Hinrichs 2014).
Vielfältig sind auch die Theorie- und Forschungsansätze zur virtuellen Realität. Je nach disziplinärer Herangehensweise können sehr vereinfacht gesagt ingenieurwissenschaftliche von human- und sozialwissenschaftlichen Ansätzen unterschieden werden. Einhergehend mit der rasanten technologischen Entwicklung nehmen aber auch zeitdiagnostische, ethische und datenschutzrechtliche Beiträge, welche die sozialen, politischen und normativen Implikationen (Chancen, Gefahren, Risiken) virtueller Realitäten diskutieren, immer mehr Raum ein (Kaminski 2016).
Im Gartner Hyper Cycle für das Jahr 2017 hat VR die Phasen des eigentlichen Hypes und die der Talsohle bereits durchlaufen und befindet sich in der Phase, in der eine Technologie nutzbringend von innovationsoffenen Unternehmen aufgegriffen und eingesetzt wird (Panetta 2017). Im Digital Trend Outlook 2016 wurde Virtual Reality als einer der größten technologischen Meilensteine des Jahres 2016 bezeichnet. Zwar dominieren beim aktuellen Angebot von VR-Brillen noch die Global Player (Oculus Rift, HTC Vive, Samsung Gear VR) den Markt, es wird aber davon ausgegangen, dass sich mit zunehmender Marktattraktivität auch kleine Anbieter im VR-Geschäft etablieren werden. Dem Gaming-Markt wird dabei eine Schlüsselrolle bei der langfristigen Durchsetzung der VR-Technologie zugesprochen. Dies liegt daran, dass die Gamer als „Early Adopter" für diese neuen Technologien angesehen werden. Weiterhin wird davon ausgegangen, dass bereits in den nächsten fünf Jahren mit einem expansiven Marktwachstum zu rechnen ist bzw. dass sich VR-Anwendungen ähnlich wie Smartphones zu einer Mainstream-Technologie entwickeln werden. Dabei schätzen 20,3 % der im Digital Trend Outlook 2016 befragten 1.057 Konsumenten die Medizin als eine wichtige Branche ein (Ballhaus et al. 2016).
Servicebasierte Infrastrukturen (SaaS, laaS, PaaS) in Kombination mit Cloud Hosting
Mit dem Begriff der servicebasierten Infrastrukturen sind Infrastrukturen, aber auch Plattformen und Software gemeint, die in einer Cloud-Umgebung ihren Nutzern zur Verfügung gestellt werden (Sommergut 2015). Unter einer Cloud-Umgebung versteht man eine IT-Umgebung, in der Rechnerressourcen, zum Beispiel Speicherplatz und Rechenkapazität, aber auch Anwendungen und Dienste, so bereitgestellt werden, dass orts- und zeitunabhängig darauf zugegriffen werden kann (BSI 2018). Unterschieden wird in der Regel zwischen öffentlichen Clouds, auf der Dienste der Allgemeinheit zur Verfügung gestellt werden, und privaten Clouds, die nur für eine Institution, zum Beispiel eine Firma, bereitgestellt werden. Außerdem sind sogenannte Community Clouds möglich, bei denen die Infrastruktur zwischen mehreren Institutionen geteilt wird. Schließlich gibt es den Begriff der hybriden Cloud, welche die gemeinsame Nutzung mehrerer Cloud-lnfrastrukturen über standardisierte Schnittstellen beschreibt.
Während die oben genannte Klassifikation vor allem die Zugriffe auf eine Cloud regelt, bildet das Drei-Schichten-Modell (Liebmann 2015) eine inhaltliche Strukturierung von Cloud-Diensten (Services) ab. lnfrastructure as a Service (laaS; z. B. Amazon EC2) bietet grundlegende Ressourcen wie Rechenkapazitäten, Speicher oder Netzwerkkapazitäten. Darauf aufbauend kann und muss ein Anwender selbst Recheninstanzen und Speicher zusammenstellen, um darauf Betriebssysteme und Anwendungen laufen zu lassen. Beim Konzept der Platform as a Service (PaaS; z.B. Windows Azure) stehen nicht nur die zuvor genannten Ressourcen zur Verfügung, sondern entsprechende Anbieter stellen Programmiermodelle und Entwicklerwerkzeuge zur Verfügung, sodass ein Anwender auf dieser Basis eigene Anwendungen erstellen und ausführen kann.
Typische Funktionalitäten bei PaaS sind die Lastverteilung zwischen Rechenknoten oder die Überwachung von Ereignissen im System. Bei Software as a Service (SaaS; z. B. Dropbox) schließlich übernimmt der Anbieter vollständig die Verwaltung der Ressourcen und des zugrundeliegenden Betriebssystems einschließlich des Einspielens von Aktualisierungen. Somit kann der Anwender von der Nutzung der Softwareanwendungen profitieren, ohne sich um technische Infrastrukturen kümmern zu müssen.
Dieser Beitrag ist ein Auszug aus der „Gutachterlichen Stellungnahme zu den Auswirkungen künstlicher Systeme und der Digitalisierung auf das kommunale Leben in Rheinland-Pfalz 2050“. Die gesamte Studie steht unter ea-rlp.de/earlpdigital2019 zum Download als PDF (88 Seiten, 18 MB) bereit.
Auszug 1 – Künstliche Intelligenz: Konzepte und Technologien
Auszug 2 – Fünf Beispiele: Chancen durch KI in Landwirtschaft, Gesundheit, Ehrenamt, Tourismus und Mobilität in RLP
Auszug 3 – Szenarien für Rheinland-Pfalz: Zwischen Dystopie und Utopie
Zusammenfassung



